Project Overview
This project provides hands-on experience with operating system concepts related to process creation, parallel execution, and performance measurement. Phase I focuses on building a Linux virtual environment, compiling and executing the provided C program, and collecting execution time results while varying the matrix size (N) and the number of processes (PROCS).
Phase I Objectives
Virtual Environment Setup
Install a VM manager and create a Linux VM to run experiments in a consistent environment.
Process Creation
Understand how fork() creates child processes and how the parent waits
using wait().
Performance Measurement
Run experiments multiple times and record execution times for different parameter settings.
Parallelism Discussion
Discuss how work is split across processes and how results change as N and PROCS change.
Deliverables (Phase I)
Required Items
- VM installation screenshots
- Linux installation screenshots
- System specifications (CPU, RAM, OS)
- Compilation + execution proof
- Execution time table(s) and graph(s)
- Discussion of observations
- Code included in appendix
What This Report Contains
- Environment setup documentation
- Program explanation (in simple terms)
- Experimental methodology (N, PROCS, 3 runs)
- Results table and summary findings
- Appendix with source code
Experimental Environment
Host System
- Host OS: macOS
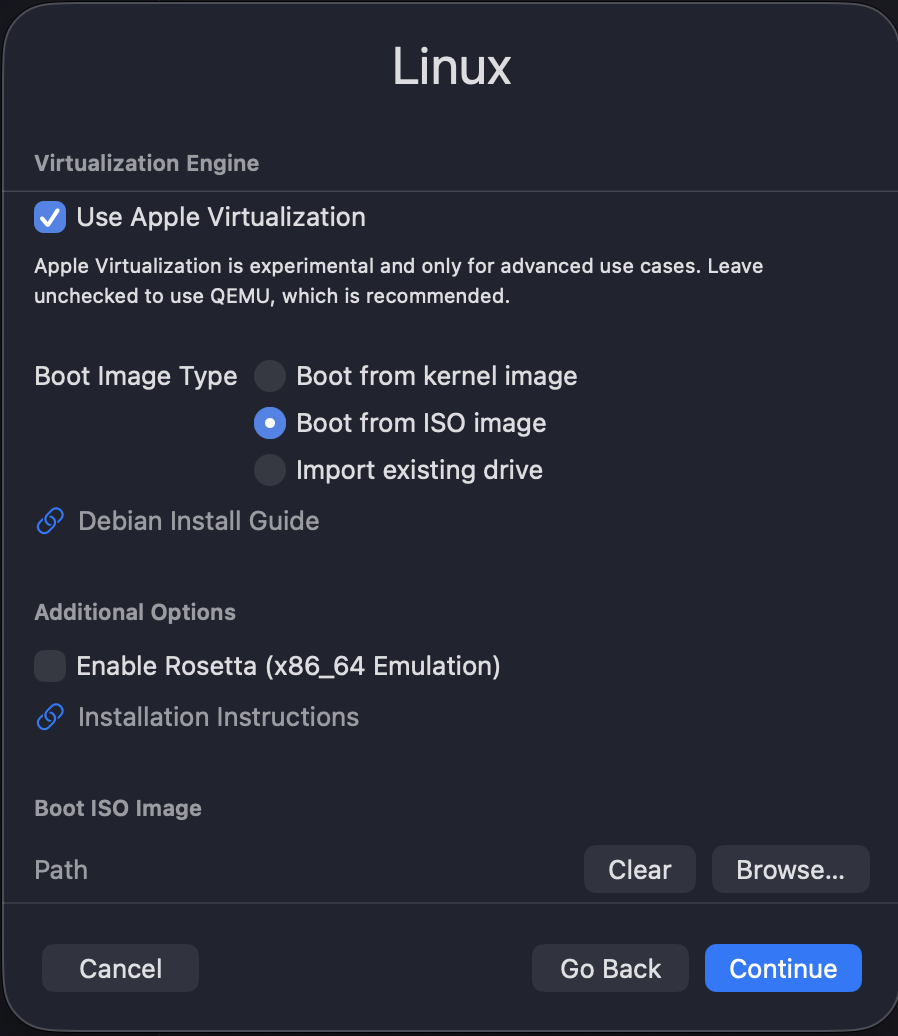
- VM Manager: UTM
- Virtualization: Apple Virtualization
Guest System
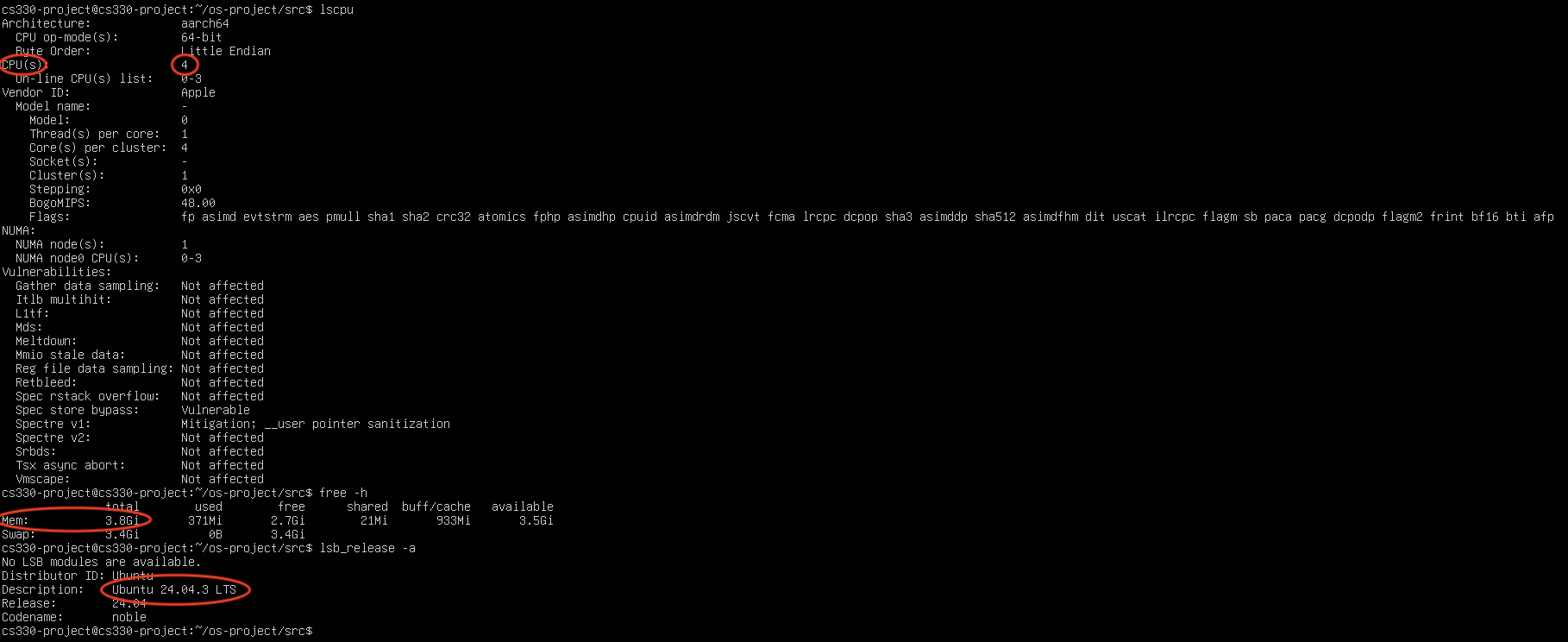
- Distribution: Ubuntu 24.04.3 LTS
- Architecture: ARM64 (aarch64)
- Kernel: Linux 6.x
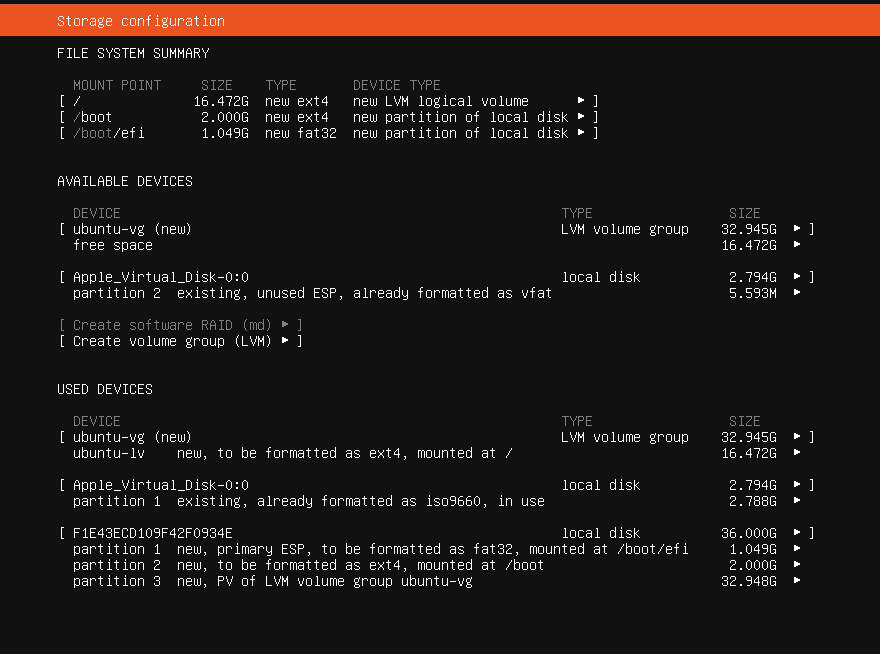
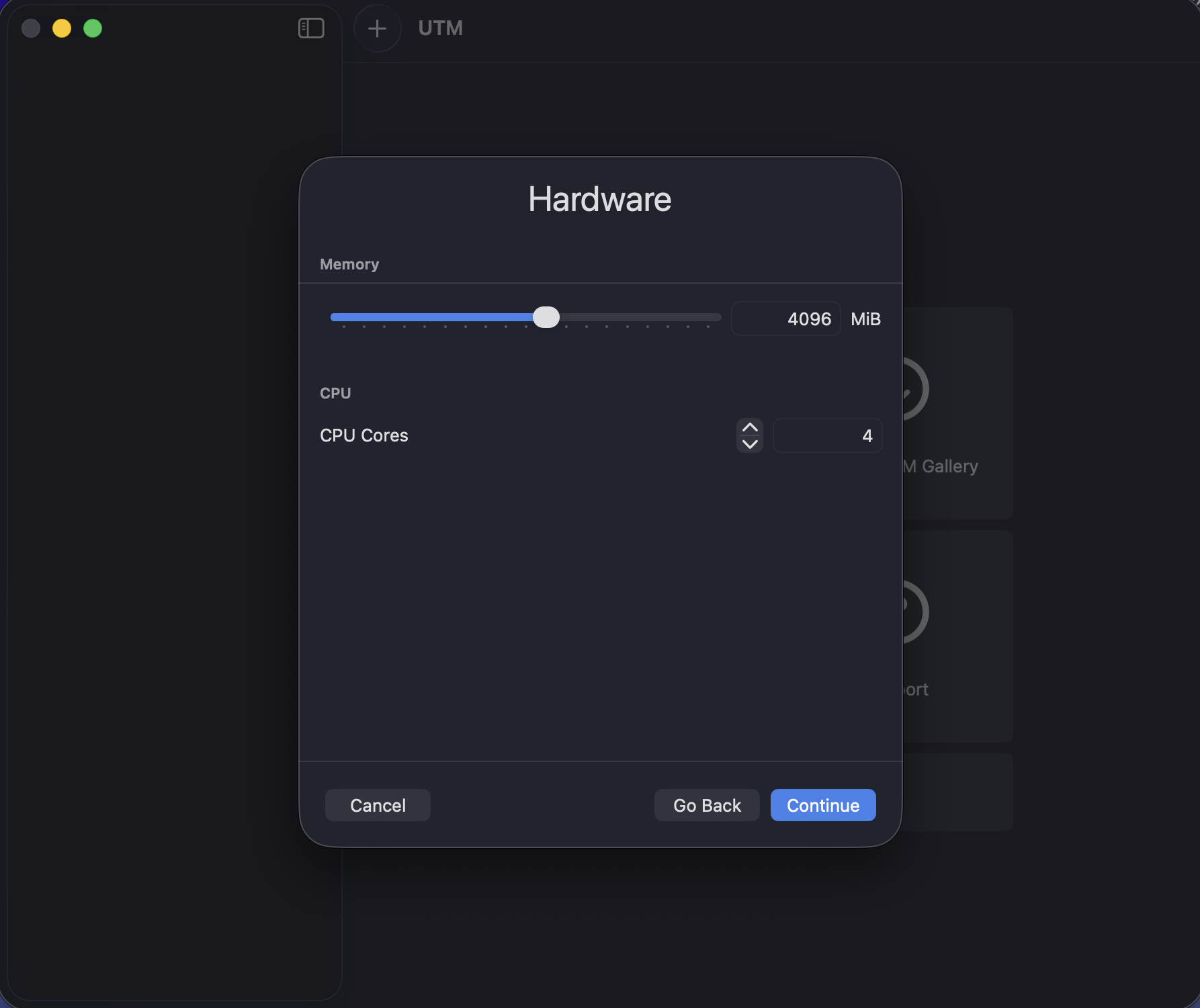
VM Resource Allocation
- CPU Cores: 4 virtual cores
- Memory: 4 GB RAM
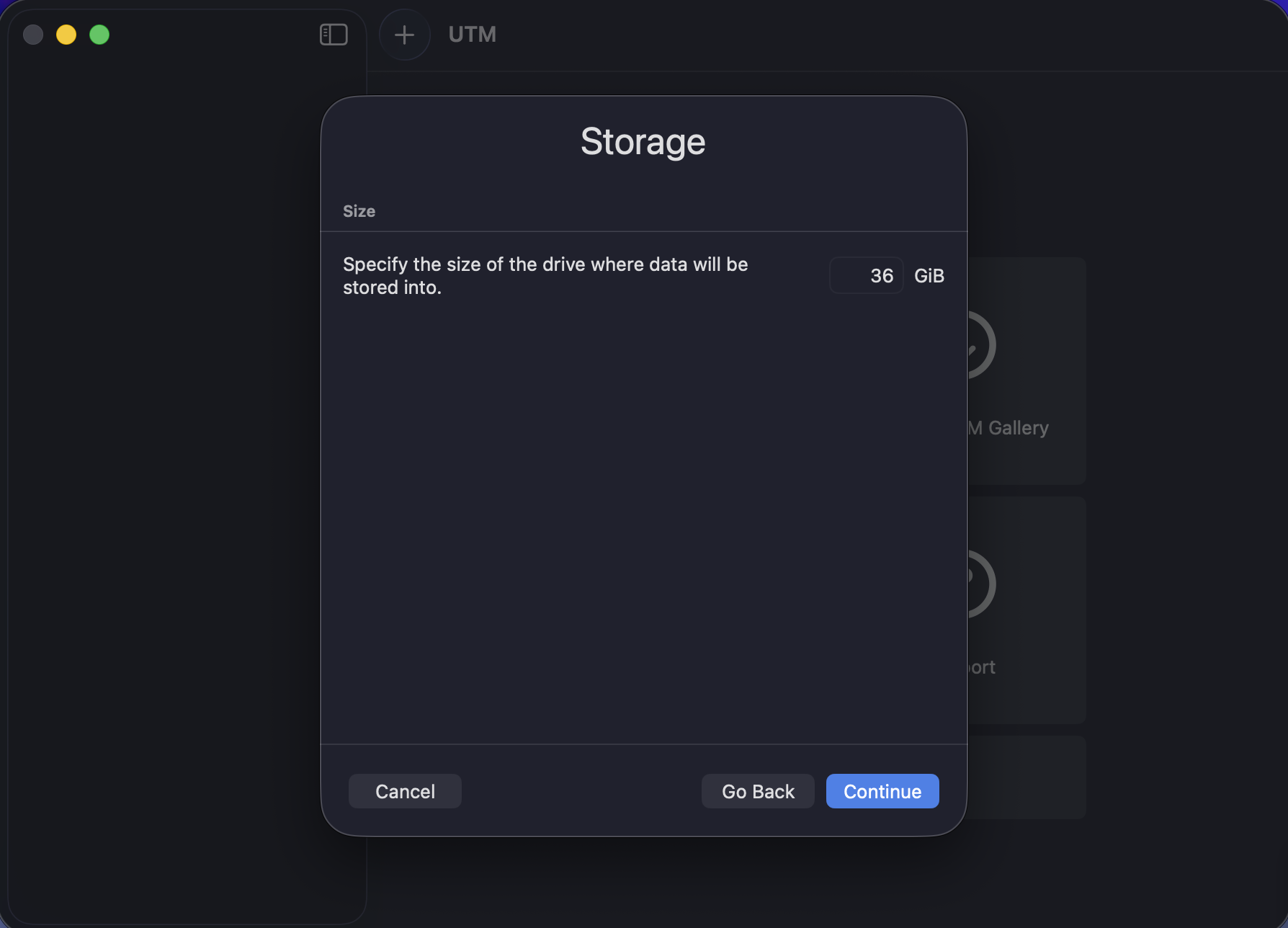
- Storage: 36 GB virtual disk
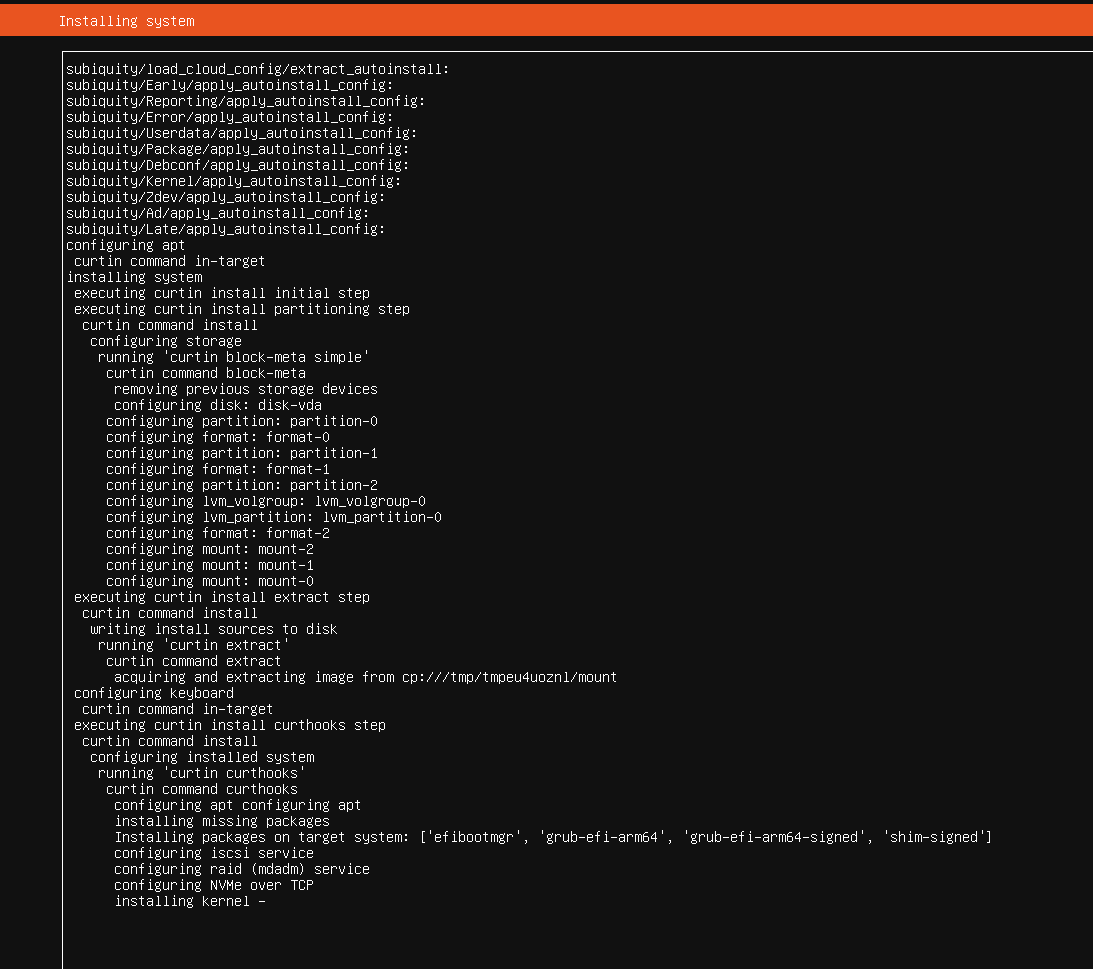
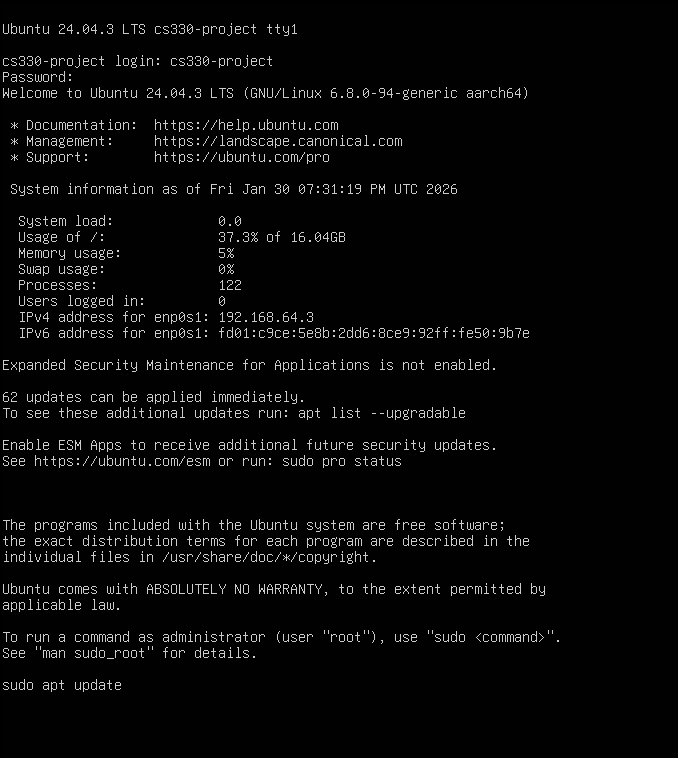
Virtual Machine Setup Gallery
The following images document the creation and installation of Ubuntu inside the virtual machine:
Software Tools Used
| Tool | Purpose | Example Command |
|---|---|---|
| GCC | Compile C code | gcc -Wall matrix_fork.c -o matrix_fork |
| Terminal | Run experiments and record output | ./matrix_fork |
| System info tools | Confirm CPU/RAM/OS | lscpu, free -h, lsb_release -a |
Experimental Methodology
Instructor-Provided Program
The program computes matrix multiplication (C = A × B). It uses fork() to create
multiple processes,
then each process multiplies a different range of rows of matrix C. The parent waits for all
child processes before
stopping the timer and printing the execution time.
#include <stdio.h>
#include // For rand(), srand(), exit()
#include // For fork()
#include // For wait()
#include // For time()
#include // For printf()
#define N 600 // Matrix size (600 x 600)
#define PROCS 4 // Number of child processes to create
// Declare three global matrices A, B, and C
double A[N][N], B[N][N], C[N][N];
// Function to fill matrices A and B with random numbers
// and initialize matrix C with zeros
void initialize_matrices() {
for (int i = 0; i < N; i++) // Loop through rows
for (int j = 0; j < N; j++) { // Loop through columns
A[i][j] = rand() % 10; // Random number (0–9) for A
B[i][j] = rand() % 10; // Random number (0–9) for B
C[i][j] = 0; // Initialize C with 0
}
}
// Function that multiplies part of the matrices
// It multiplies rows from "start" to "end"
void multiply(int start, int end) {
for (int i = start; i < end; i++) // Loop through assigned rows
for (int j = 0; j < N; j++) // Loop through columns
for (int k = 0; k < N; k++) // Multiply row by column
C[i][j] += A[i][k] * B[k][j]; // Matrix multiplication formula
}
int main() {
srand(time(NULL)); // Seed random number generator
initialize_matrices(); // Fill matrices A and B
clock_t start_time = clock(); // Start measuring time
int rows_per_proc = N / PROCS; // Divide rows equally among processes
// Create child processes
for (int p = 0; p < PROCS; p++) {
pid_t pid = fork(); // Create new process
if (pid == 0) { // If this is the child process
int start = p * rows_per_proc; // Starting row for this process
// Last process takes remaining rows (in case N not divisible)
int end = (p == PROCS - 1) ? N : start + rows_per_proc;
multiply(start, end); // Perform multiplication on assigned rows
exit(0); // Child finishes and exits
}
}
// Parent waits for all child processes to finish
for (int p = 0; p < PROCS; p++)
wait(NULL);
clock_t end_time = clock(); // Stop measuring time
// Calculate execution time in seconds
double time_taken = (double)(end_time - start_time) / CLOCKS_PER_SEC;
printf("Execution Time: %.3f seconds\n", time_taken); // Print result
return 0; // End of program
}
}
Simple Explanation of What Each Part Does
Matrices and Initialization
The program uses three global matrices: A and B are filled with random numbers, and C is initialized to 0. This guarantees the multiplication does real work each run.
fork() and Process Creation
The loop creates PROCS child processes using fork(). The
parent continues creating children,
and each child performs computation then exits.
Work Splitting (Row Ranges)
The total number of rows in the result matrix C is N. To distribute the work among the
child processes,
the program first calculates rows_per_proc = N / PROCS. This determines how
many rows each process
should compute at minimum. Each process is assigned a unique starting row using
start = p * rows_per_proc, and normally computes rows up to
start + rows_per_proc. This ensures that no two processes work on the same
rows.
If N is not exactly divisible by PROCS, the last process is assigned all remaining rows
(by setting its end row to N), so that every row of matrix C is computed exactly once
and no rows are skipped.
Waiting and Timing
The parent waits for all processes using wait(NULL).
After all children finish, the program stops the timer and prints the execution time.
Compilation and Execution
- Compile:
gcc -Wall matrix_fork.c -o matrix_fork - Run:
./matrix_fork - Repeat: Run 3 times per configuration and record the output time
Experimental Variables Used in This Report
Matrix Size (N)
N controls the matrix dimension and directly impacts the workload. Larger N means more multiplication work.
Number of Processes (PROCS)
PROCS controls how many child processes are created and how the rows are split across them.
Experimental Results

Execution Time Table
The following table shows the execution time for each configuration. Each configuration was executed three times and an average time was recorded.
| Matrix Size (N) | Processes (PROCS) | Run 1 (s) | Run 2 (s) | Run 3 (s) | Average Time (s) |
|---|---|---|---|---|---|
| 1200 | 1 | 0.001 | 0.001 | 0.003 | 0.0016 |
| 1200 | 4 | 0.002 | 0.002 | 0.001 | 0.0016 |
| 1800 | 1 | 0.001 | 0.001 | 0.001 | 0.0010 |
| 1800 | 4 | 0.003 | 0.003 | 0.003 | 0.0030 |
| 2400 | 1 | 0.002 | 0.001 | 0.001 | 0.0013 |
| 2400 | 4 | 0.004 | 0.003 | 0.003 | 0.0033 |
Average Time Comparison
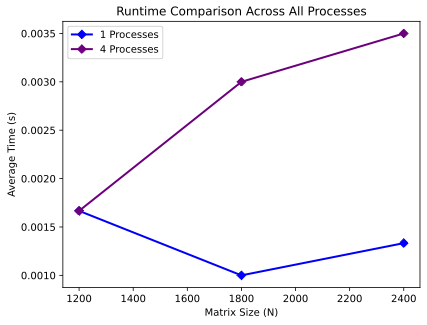
Average execution time comparison between PROCS = 1 and PROCS = 4 for different matrix sizes (N).
Summary of Observations From the Table
Direct Table Observations
- For N=1200, PROCS=1 and PROCS=4 had the same average time (0.0016 s).
- For N=1800 and N=2400, PROCS=4 was slower than PROCS=1 based on the measured averages.
- Results show that increasing the number of processes did not reduce the measured time for these configurations.
Why Multiple Runs Matter
Running each configuration multiple times helps reduce random variation. Small measured times can vary due to system scheduling and timing granularity, which is why averaging is useful.
Analysis & Discussion
Task Parallelism vs. Data Parallelism (In This Program)
Task Parallelism
Task parallelism appears because multiple processes run at the same time. Each child process performs a portion of the computation while the operating system schedules them across CPU cores.
Data Parallelism
Data parallelism appears because the program splits the data (rows of the result matrix C) between processes. Each process calculates a different range of rows, so no two processes are assigned the same row range.
What Happened in Our Results
Main Finding
For the tested configurations, using 4 processes did not improve the measured execution time compared to 1 process. In some cases, the measured time with 4 processes was higher.
Why More Processes Can Be Slower (Simple Explanation)
fork() Overhead
Creating processes using fork() has a cost. The OS must create a child
process and manage it,
which adds overhead that may be noticeable if the computation time is small.
Scheduling and Context Switching
When multiple processes run, the OS scheduler switches between them. This scheduling activity can add extra work, especially when the program is short or when the timing values are very small.
Memory and Cache Effects
Matrix multiplication touches many memory locations. When multiple processes run, they compete for CPU cache and memory bandwidth, which can reduce performance instead of improving it.
Timing Resolution
When reported execution times are very small (in milliseconds), small variations can significantly affect the results. That is why we repeated runs and used averages.
How the Work Was Split (Rows Per Process)
The program splits the matrix rows using rows_per_proc = N / PROCS.
For example, when PROCS=4, each process gets approximately one quarter of the rows.
The last process handles any remaining rows to ensure all rows are computed.
Conclusion
Summary
In Phase I, we successfully installed a Linux virtual machine environment, compiled and
executed the instructor-provided
C program that uses fork() to create multiple processes, and collected
execution time results across multiple runs
while varying matrix size (N) and number of processes (PROCS).
Key Conclusions (Based on Our Measurements)
Environment and Setup
- Ubuntu VM was installed and configured successfully
- System specifications were verified (CPU, RAM, OS)
- Program compiled and ran correctly in the VM
Performance Findings
- For the tested configurations, PROCS=4 did not reduce execution time compared to PROCS=1
- Some configurations showed higher measured time when using more processes
- Multiple runs helped capture variation and allowed averaging
What This Demonstrates (Operating Systems Concept)
This experiment demonstrates that process-based parallelism can have overhead (process creation, scheduling, and resource contention). Whether parallelism improves performance depends on the workload size and the cost of managing multiple processes.
Appendix
.png)
Complete Source Code Used
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
#include <time.h>
#define N 600
#define PROCS 4
double A[N][N], B[N][N], C[N][N];
void initialize_matrices() {
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
A[i][j] = rand() % 10;
B[i][j] = rand() % 10;
C[i][j] = 0;
}
}
}
void multiply(int start, int end) {
for (int i = start; i < end; i++) {
for (int j = 0; j < N; j++) {
double sum = 0;
for (int k = 0; k < N; k++) {
sum += A[i][k] * B[k][j];
}
C[i][j] = sum;
}
}
}
int main() {
srand(time(NULL));
initialize_matrices();
clock_t start_time = clock();
int rows_per_proc = N / PROCS;
for (int p = 0; p < PROCS; p++) {
pid_t pid = fork();
if (pid == 0) {
int start = p * rows_per_proc;
int end = (p == PROCS - 1) ? N : start + rows_per_proc;
multiply(start, end);
exit(0);
}
}
for (int p = 0; p < PROCS; p++) {
wait(NULL);
}
clock_t end_time = clock();
double time_taken = (double)(end_time - start_time) / CLOCKS_PER_SEC;
printf("Execution Time: %.3f seconds\n", time_taken);
return 0;
}
Additional System Screenshots